
哈哈,居然撑到第二期了.jpg
让我们用 ICLR 2026 submission 的新闻开场吧。
1. Mamba-3
标题:Mamba-3: Improved Sequence Modeling using State Space Principles
概览:Mamba-3 仍然坚持使用 SSM 范式,整体来说感觉是一个理论贡献大于实际贡献的文章。改动在于:
-
在离散化中使用推广梯形法则替代欧拉法的零阶保持,说人话就是在估计区间积分的时候把替代点从区间的左端点换成了自适应的某个中间插值点。并证明了这种方式与 short conv 能够形成类似的 pattern,能够代替 short conv 的作用。这是我个人最不认可的一点,因为它推出来长下面这样。这和直接算卷积有什么不一样吗我请问了()算是从 SSM 视角提供了一个理论贡献吧。
-
状态转移矩阵复值化。原本 SSM 的转移矩阵就是复值的,在发展到 mamba-2 的过程中逐渐简化掉了。但在简化的过程中损伤了模型的状态追踪能力,因此 mamba-3 又加回来了。它证明复值的转移矩阵等价于 2x2 diagonal block 构成的转移矩阵,又等价于在 BC 两个矩阵上施加有数据依赖的 RoPE(具体没看)。这是我个人最感兴趣的一点,但这个问题应该挺值得挖掘的。
-
为了在 decoding phase 达到 compute bound,mamba-3 选择在状态更新中再加一个维度增加计算量,反正挺离谱的。这个改动实际上提高了推理延迟,但是应该提高了算术强度。作者或许也觉得这个改动不是特别妥当,是一个可选项。
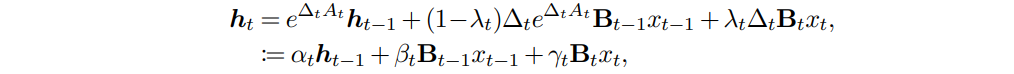
测试是标准的 100B token 训练,但是长度只有 2k,他们或许根本就没有想做外推。常规任务和 gated delta 有来有回,最多也就是几个点。长文本情况也差不多,比 mamba-2 好点。不知道涨点是从哪里来的,没有 ablation 环节。
2. Twilight
标题:Twilight: Adaptive Attention Sparsity with Hierarchical Top-p Pruning
概览:简单来说就是 top-p selection。常用的 top-k selection 有很显著的缺陷,即 k 是手动指定的,这意味着 top-k sparse attention 的内存预算和 sliding window attention 实际上是一样的,只不过它可以自己决定这个空间里可以放什么。显然不是所有时候都可以一个恒定的内存预算中完成全部的任务;top-k 只是算起来比较简单而已(指在内核编写上)。
这篇文章其实就没有别的内容了。其他的部分都是非常工业的考虑,比如 top-p 对 kv cache 的精度要求比 top-k 要高,因为 top-k 实际上只要比较 attention score 之间的相对大小,甚至不需要经过 softmax 就可以选出需要的 token。但是 top-p 是确实需要选出 attention score 总和超过阈值的 token,因此有更高的精度要求,但实际上也只是 4bit kv cache 而已。另外还有 top-p 如何计算的问题,因为朴素的 top-p 计算需要累加的操作。文中的 kernel 是从 FlashInfer 改编来的,使用的是二分查找的方式;即确定一个下界,一个上界,一个中间的 pivot,看看 pivot 到最大值之间的值加起来是不是超过 p。如果是,说明选多了,pivot 上移;如果不是,说明选少了,pivot 下移。另外整个方法是建立在传统的 top-k 方法之上的,它使用 top-k 进行粗选(保留 1/4 上下文的预算),然后再使用 top-p 进行精细的选择。也就是题目中 hierarchical 的来源。
3. DeepSeek-OCR
标题:DeepSeek-OCR: Contexts Optical Compression
概览:上一版同步的时候被吞了,重新写一遍。这个模型本质上是一个文本上的 autoencoder,输入是含有文字的图片,输出是原始的文本。通过视觉处理中的降采样压缩 latent space 中的 token,实现了相比文本 tokenizer 大约 10x 的空间压缩,同时保留文本还原的精度(即依然能够从 latent space 中还原出原始的文本)。它通过这种方式证明,传统的文本模态实际上存在很大的压缩空间。
4. Cognitive Map Learner
标题:Local prediction-learning in high-dimensional spaces enables neural networks to plan
概览:Wolfgang Maass 在 talk 中提到的工作,是一个尝试使用基本的可塑性规则进行 planning 的工作。两个 one-hot 编码的向量,一个是 observation,或者说当前的状态;一个是 action,或者说当前能够采取的行动。这两个 one-hot 编码分别使用一个权重矩阵编码到一个相同的空间中去,并且进行预测编码,即
以这个目标进行 loss 和 backprop,将会得到和的更新方程,全部都遵循 Hebb 规则。当这两个矩阵大致符合上面的规则之后,实际上就建立了一个待求解问题的 cognitive map。比如,待求解问题是图上最短路径,在图上先进行随机游走,通过的样本更新以上权重。这里的 observation 实际上就是当前的 node,action 就是允许的边,下一个 observation 就是下一个节点。当更新完成之后,权重中实际上包含了对整个图的形态的认知。
在完成建模之后,可以进行决策。在得到的空间中,所有的 state/observation 被视为点坐标,而一个 action 被视为一个位移,决策实际上就是找出一系列的 action,使其能够完成源 observation 和目标 observation 之间的位移。要完成最优化则采用贪心策略,即通过当前状态与目标状态之间相差的方位和待检查的 action 之间的点积来进行判断。寻找最优的 action 就是把所有的 action 都进行一次度量,然后使用 winner-take-all 的策略选出一个 action。
为了能够使用贪心策略,实际上要求所有的 之间大致是正交的,另外还要求所有的 之间模长大致相同。这是通过从高斯分布中随机初始化完成的(近似正交,并指望模长在训练中保持稳定)。
这个模型包含了 Markov 性质的假设,即当前的 action 仅仅是由当前的 observation 决定的。另外在文章最后一部分说明了和 attention 的相似性。这个决策过程实际上看起来就是很像 atttention:使用当前的,检查所有的,然后使用 top-1 而非 softmax 的策略进行选择,key 和 value 是一样的。
5. LoopLM
标题:Scaling Latent Reasoning via Looped Language Models
概览:来自字节的工作,架构上是一个标准的 Transformer,循环的部分是 embed 之后、lmhead 之前的堆叠层,是把整体看作一个循环单位。最后接了一个 exit gate。因为是这样一个架构就没有再看下去,和 coconut 实际上差不多吧。更多是工业上的考虑。
6. Interactions between long- and short-term synaptic plasticity transform temporal neural representations into spatial
标题:如题
概览:和 tempotron 同类的工作,感觉意义不大,只作记录。主要探讨了 n 对 1 连接下,允许连接强度在单次 trial 的不同 spike 之间进行动态调整(短期 plasticity)可能带来的性能提高。如果调整策略足够聪明,使得在不同的 spike 之间进行任意的调整,那么实际上相当于变相地增加了突触的数量,作者称为 (ideal) ordinal plasticity。作为一个更实际的模型,作者验证了 Tsodyks–Markram model 递质传递模型带来的可塑性。实验证明 TM model 带来的可塑性增益大致相当于将权重数量翻倍。这实际上是时序上的增益(因为 plasticity 必须要在时间上起作用)向空间上的增益(权重翻倍)的等价,所以如题。
7. EFLA
标题:Error-Free Linear Attention is a Free Lunch: Exact Solution from Continuous-Time Dynamics
概览:建议直接看苏剑林的写法,一些数学的部分再回原文去补。它的主要贡献是给出了 delta rule 下的连续形式:
在后半部分的式子中,我们去掉了时间下标,因为在求解区间内,这两个矩阵暂时被视为恒定矩阵。需要注意的是,这种连续写法与SSM中的连续写法并不对应。DeltaNet可以视为上述连续过程单步离散化求解的结果,或者说最简单的ode离散方式。EFLA给出了连续形式的解析解,最后得到的式子看起来和DeltaNet基本是一致的,只不过规则自身携带了L2Norm的形式,并且写入门稍微复杂一些。效果上和DeltaNet没有差太多,因为形式上基本上也是一样的。
8. E2E-TTT
标题:End-to-End Test-Time Training for Long Context
概览:如图。
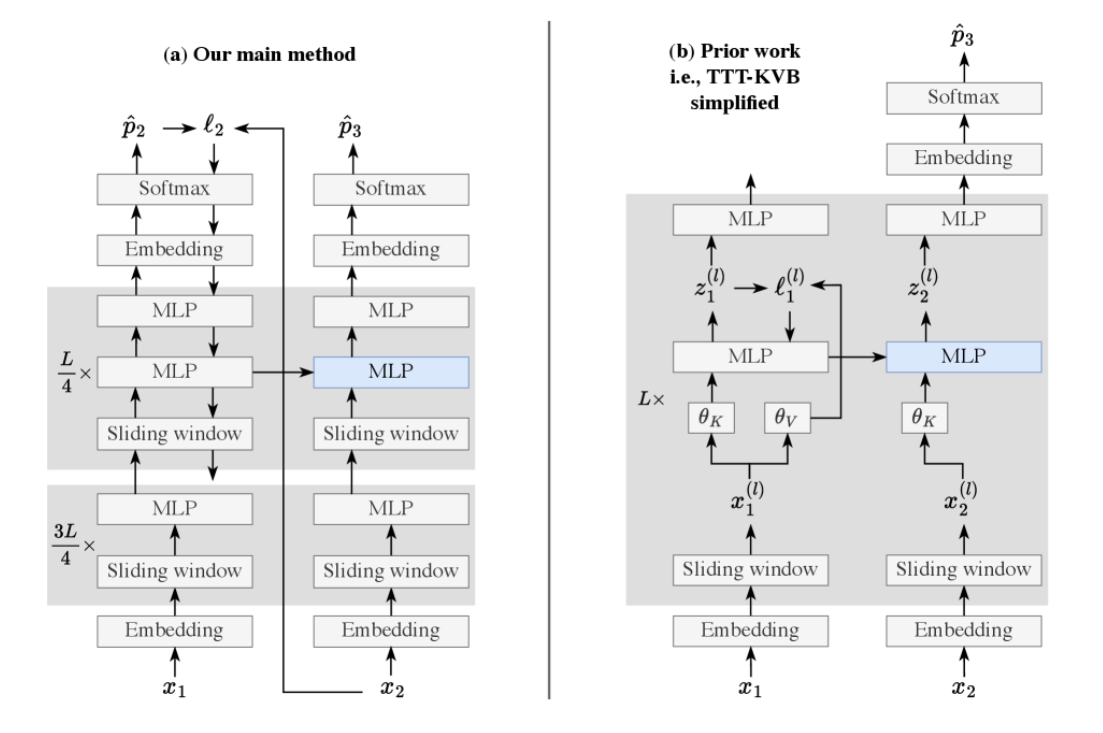
实际上就是以前的TTT是内部的memory使用内部的重建损失进行局部的优化,这篇工作将这种做法扩展到了使用全局的CE损失进行优化。每进入一个token,得到它对应的CE,然后直接进行梯度传播,将MLP的权重进行动态更新,以此作为一种将上下文直接压缩到权重的方法。实际上为了梯度稳定和计算效率是每个chunk更新一次,而且这个chunk还是挺大的,有1k之长。另外为了减少计算开销只有后部的1/4层参与了TTT的计算,并且为了绕开持续学习的问题,在参与TTT的层中每个层都叠了两个MLP,以保证安全的commonsense。整体来说是一个在SWA的基础上使用TTT附加全局视野的工作,实验效果(尤其是NIAH)和GDN差不多。
9. Nested Learning
标题:Nested Learning: The Illusion of Deep Learning Architectures
概览:还是google的TTT的文章。前面三十多页全是一些变体,具体的架构放在最后面。这篇文章中最后使用的架构是一层self-referential Titans后接多层MLP,其中每层MLP设置了不同的更新频率。所谓的self-referential Titans就是标准的linear attention架构,但是qkv和两个门的变换权重全部使用在线更新的权重,美其名曰能够将上下文的信息融入qkv,避免shortconv造成的短视,但实际上还是把L2Norm和shortconv加上了,有点难绷。所有权重都使用delta规则进行更新,不过稍有不同,准确来说是基于delta的梯度下降。所有的memory依旧还是两层带残差的MLP。
Comments NOTHING